VMware vSphere 7 VM DRS Scores
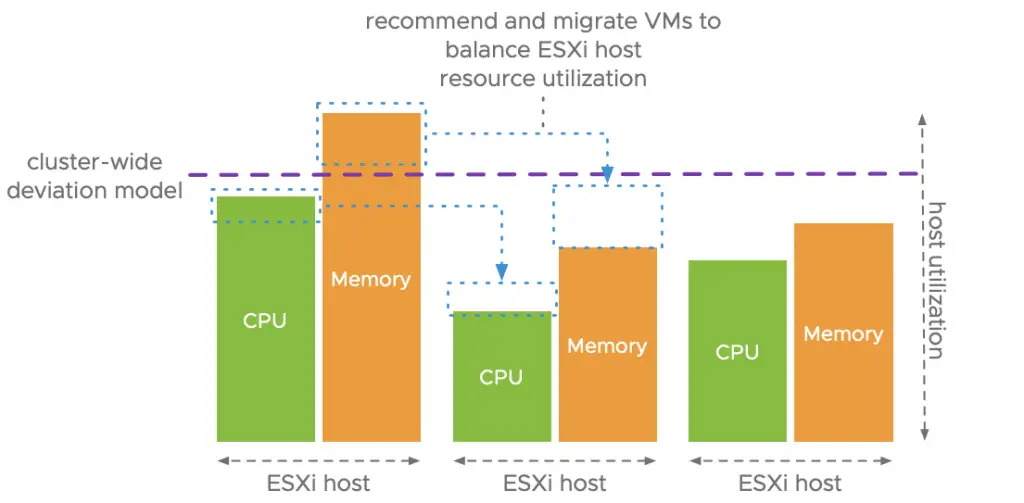
In previous vSphere versions, DRS used cluster-wide standard deviation model calculations to maximise workload ‘happiness’ as seen in the diagram below.
In essence, this means that DRS based on the ESXi host usage baseline, a particular threshold range that can be adjusted using the DRS migration threshold.
The re-vamped logic of the DRS takes a somewhat different approach from its predecessor.
The new DRS logic quantifies virtual machine happiness by using the VM DRS score. First of all, let me stress that the VM DRS Score is not a health score for a virtual machine!
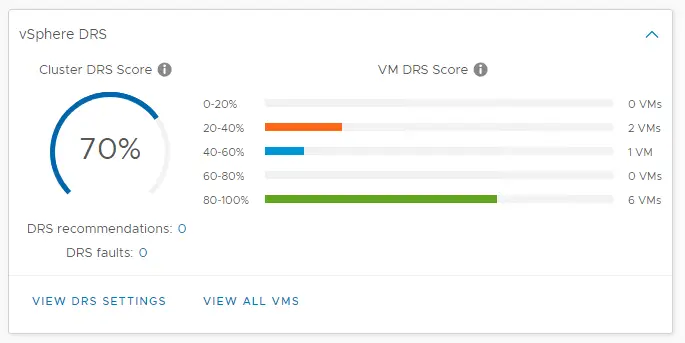
It’s about the execution efficiency of a virtual machine (VM). The scores vary from 0 to 100 percent and are divided into buckets, 0-20 percent, 20-40 percent, and so on.
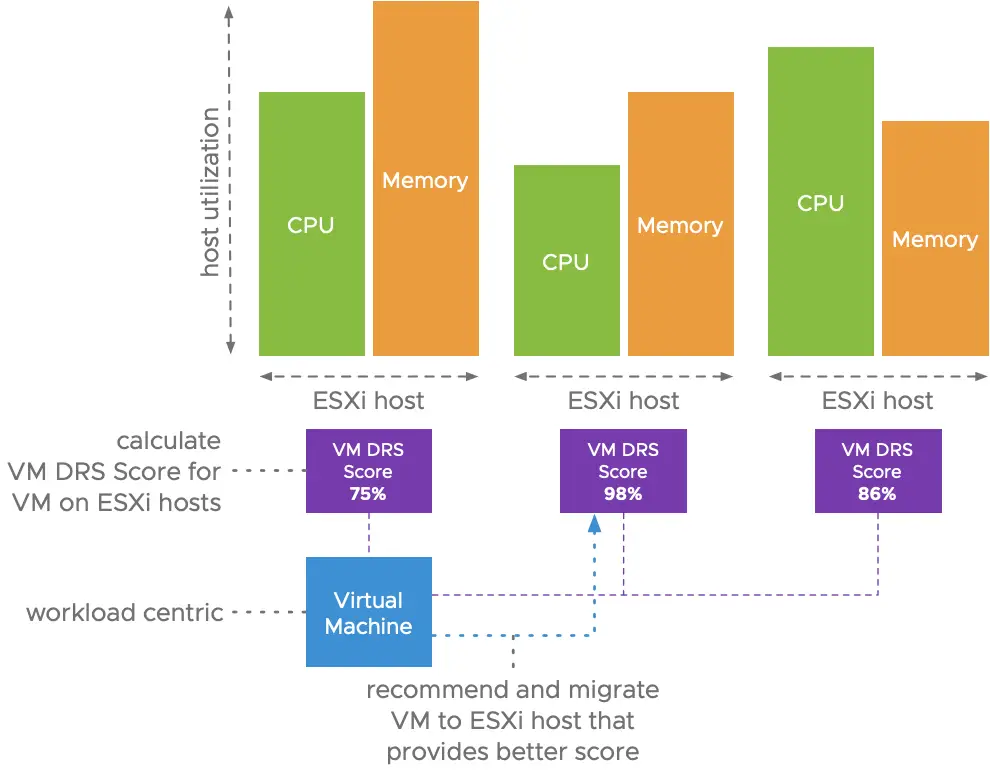
Obtaining a VM DRS score of 80-100 percent suggests that there is little to no resource contention. It doesn’t inherently mean that a virtual machine in the 80-100 percent bucket is doing better than a virtual machine in the bottom bucket.
That’s because there are a number of metrics that affect the score of the VM. Not only performance metrics are used, but capacity metrics are also incorporated into the algorithm.
Performance drivers for the VM DRS score are contention dependent, using metrics such as CPU% Ready Time, good CPU cache behaviour, and memory swap.
The reserve resource capacity or headroom of the current ESXi host is also taken into account to assess the VM DRS ranking. Would this virtual machine be able to burst resource usage on its current host and at what level?
Goodness VM DRS Modelling
The fundamental principle of the new logic of DRS is that VMs have the ideal throughput and true throughput for each resource (CPU, memory, and network). If there is no contention, the ideal throughput of the VM is equal to the real throughput.
We care about resource contention when several VMs are in contention over access to a shared machine or network resource. Migration cost is also considered in this modelling.